When dealing with large text collections, it can be difficult to understand the themes or subjects they contain. Topic identification, also called topic modelling, helps uncover these hidden topics automatically. Now, one of the most widely used methods for this is Latent Dirichlet Allocation (LDA), and the Gensim library in Python makes it easy to apply.
Yet, there is a challenge. How do you make sure the topics are clear, meaningful, and not repetitive? Two things guide this – how well the text is prepared, and how you choose the right number of topics.
In this tutorial, we’ll walk through both. From cleaning your text to tuning your model, so you get useful, high-quality topics every time.
Table of contents
Introduction
Automatically extracting the themes people are talking about from enormous volumes of text is one of the fundamental applications of natural language processing. Large text examples include social media feeds, consumer evaluations of hotels, movies, and other businesses, user comments, news pieces, and e-mails from customers with concerns.

Businesses, administrators, and political campaigns benefit greatly from knowing what people are talking about and understanding their concerns and viewpoints. Manually reading through such vast volumes and compiling the themes is difficult.
As a result, we require an automated system to read through text documents and automatically churn out the output we seek.
In this study, we’ll use the ’20 Newsgroups’ dataset as a real-world example to extract naturally discussed themes using LDA.
Fundamentals of Topic Identification
Here, we will cover the principles of subject identification and modeling. We will also learn how to detect topics from texts using the bag-of-words approach and simple NLP models.
Pipeline of Data
I have pre-processed the raw text data for the data pipeline using RegEx and other normalization capabilities. I use exploratory data analysis (EDA) to learn how the data is distributed and structured so that I can optimize the preprocessing. Topic identification models are then developed using Python frameworks. We can always return from model development to EDA and make it an iterative process, in the sense that we can learn more about which methods are best for our particular data and goal. Once we have an ultimate model, we can use Docker, AWS, or another cloud provider to scale it up to be a production model.
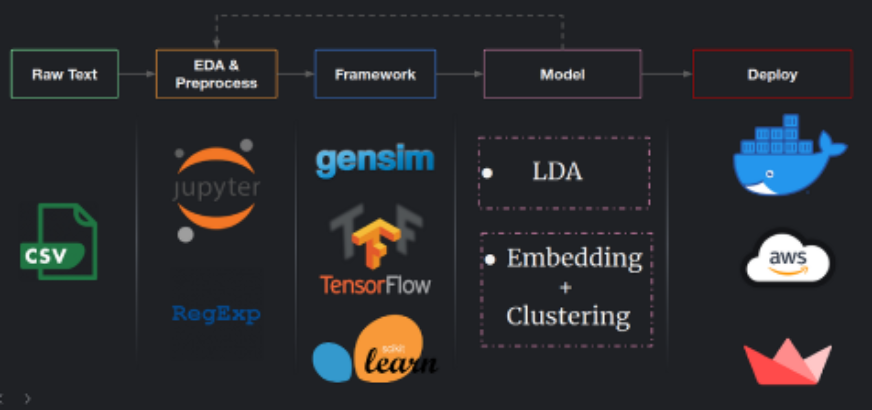
The Bag-of-Words Method
The bag-of-words method is a simple way to identify subjects in a document. It is better to use a term as frequently as possible.
Text Preparation
Although the material given above is intriguing, it is not useful for subject identification. This is because tokens such as ‘the’ and ‘was’ are common terms that help little with topic identification. We’ll use text preparation to get around this.
Word Lemmatization
Lemmatization refers to the reduction of words to their roots or stems.
The first line of code creates WordNetLemmatizer. Second-line calls in the Counter class and generates a new Counter called bag words, while the third line calls the ‘.lemmatize()’ method to build a new list called LEM tokens. The fourth line displays the six most prevalent tokens.
lemmatizer = WordNetLemmatizer() lem_tokens = [lemmatizer.lemmatize(t) for t in stopwords_removed] bag_words = Counter(lem_tokens) print(bag_words.most_common(6))
Gensim and Latent Dirichlet Allocation (LDA)
Gensim is an open-source natural language processing (NLP) library that may create and query corpus. It operates by constructing word embeddings or vectors. These are then used to model topics.
Deep learning algorithms build multi-dimensional mathematical representations of words, called word vectors. They provide information about the relationships between terms in a corpus. The distance between the words ‘India’ and ‘New Delhi,’ for example, may be comparable to the distance between the words ‘China’ and ‘Beijing,’ as these are the ‘Country-Capital’ vectors.
Gensim for creating and querying the corpus
It’s time to put what you’ve learned in the previous video to work and develop your first gensim dictionary and corpus!
We will use these data structures to explore word trends and uncover interesting themes in your document set. To start, we imported a few additional Wikipedia articles and preprocessed them by lowercasing all words, tokenizing the text, and removing stop words and punctuation. We then saved the cleaned documents as a list of tokens called articles. Before we create the Gensim vocabulary and corpus, you’ll need to complete some initial setup.
Gensim’s bag of words
Now you will use your new gensim corpus and dictionary to see which terms are most frequently used in each document and across all documents. You can look up the terms in your dictionary.
To assist with the generation of intermediate data structures for analysis, you have access to the dictionary and corpus objects you created in the last exercise, as well as the Python defaultdict and itertools.
We can use defaultdict to create a dictionary that assigns a default value to non-existent keys. We may ensure that any non-existent keys are automatically allocated a default value of 0 by using the int parameter.
Document-Term Matrix for LDA
After creating the document-term matrix, we will train the LDA model directly on it. In the first line of code below, we pass the document-term matrix to the LDA object to begin the training process. The number of topics and the dictionary must also be specified. We may limit the number of subjects to two or three because we have a tiny corpus of nine documents.
When texts are coherent within themselves, bag-of-words information (LDA or TF-IDF) is excellent for identifying topics by detecting frequent words. Incoherent texts, whether due to word choice or unclear meaning, demand more contextual information to clearly convey their ideas.
Tf-idf with gensim
TF-IDF
Term Frequency – Inverse Document Frequency
1) Allows you to discover which words in each document are the most significant.
2) Beyond stop words, each corpus may have shared words.
3) The importance of these words should be reduced.
4) Ensures that the most common words aren’t used as keywords.
5) Maintains a high-weighted document with specified frequent words.
formula
Wi,j = tfi,j * log(N/dfi)
- wi,j= tf-idf for token ii in document jj
- tfi, j =tfi,j= number of occurrences of token ii in document jj
- dfi =dfi= number of documents that contain token ii
- N = total number of documents
Download the datasets from sklearn
I used the 20Newsgroup data set, under sklearn datasets, which downloads quickly.
from sklearn.datasets import fetch_20newsgroups newsgroups_train = fetch_20newsgroups(subset=’train’, shuffle = True) newsgroups_test = fetch_20newsgroups(subset=’test’, shuffle = True)
The news in this data set is already categorized into key topics. Which you can get by.
print(list(newsgroups_train.target_names))

Looking at the data set visually, we can see that it covers a variety of themes, such as science, politics, sports, religion, and technology. Let’s look at some examples of recent news.

Data Preprocessing
The following are the steps we’ll take:
1) Split the text into sentences and the sentences into words using tokenization.
2) Remove all punctuation and lowercase words.
3) Words with fewer than three characters are omitted.
4) All stopwords have been eliminated.
5) Nouns are lemmatized, so third-person words are transformed to first-person, and past and future tense verbs are changed to present tense.
6) Words are stemmed, which means they are reduced to their simplest form.
Download nltk stop words and necessary packages
import gensim
from gensim.utils import simple_preprocess
from gensim.parsing.preprocessing import STOPWORDS
from nltk.stem import WordNetLemmatizer, SnowballStemmer
from nltk.stem.porter import *
import numpy as np
np.random.seed(400)
import nltk
nltk.download('wordnet')
Lemmatizer:
Let’s have a look at a lemmatizing example before we start preprocessing our data. What would happen if we lemmatized the word “Gone”?
we are converting the past tense to present tense here,
print(WordNetLemmatizer().lemmatize('gone', pos = 'v'))
Output: go
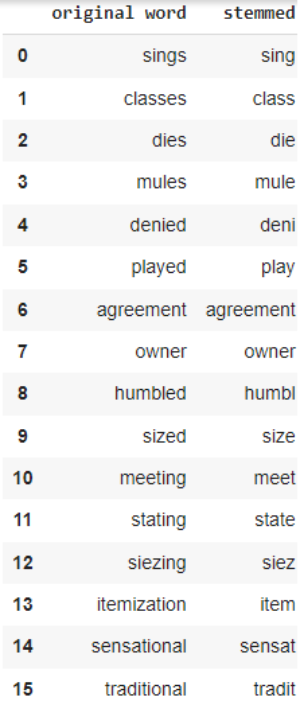
Let’s look at a stemming example as well. Let’s try throwing a few words at the stemmer and see how it responds:
import pandas as pd
stemmer = SnowballStemmer("english")
original_words = ['sings', 'classes', 'dies', 'mules', 'denied','played', 'agreement', 'owner',
'humbled', 'sized','meeting', 'stating', 'siezing', 'itemization','sensational',
'traditional', 'reference', 'colon','plotting']
singles = [stemmer.stem(plural) for plural in original_words]
pd.DataFrame(data={'original word':original_words, 'stemmed':singles })
Output:
Let’s write a function that runs through the pre-processing stages for the entire dataset.
def lemmatize_stemming(text):
return stemmer.stem(WordNetLemmatizer().lemmatize(text, pos='v'))
# Tokenize and lemmatize
def preprocess(text):
result=[]
for token in gensim.utils.simple_preprocess(text) :
if token not in gensim.parsing.preprocessing.STOPWORDS and len(token) > 3:
result.append(lemmatize_stemming(token))
return resul
Let us now preview a document after preprocessing and get the tokenized and lemmatized document.
document_number = 50
doc_sample = 'Sara did not like to read. She was not very good at it.'
print("Original document: ")
words = []
for word in doc_sample.split(' '):
words.append(word)
print(words)
print("nnTokenized and lemmatized document: ")
print(preprocess(doc_sample))
output:

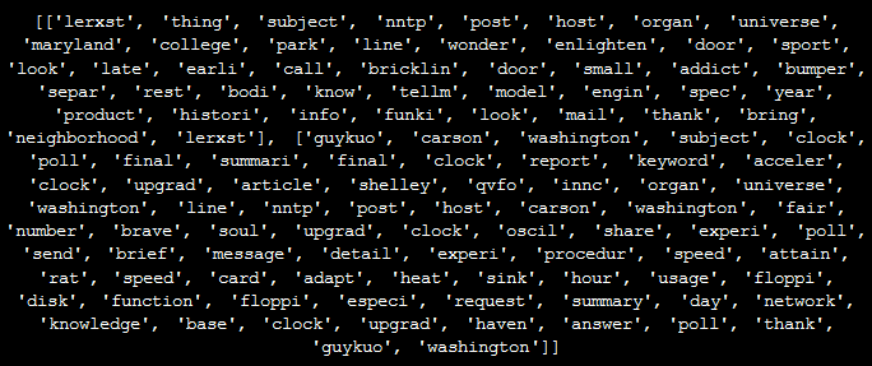
Let’s start by preprocessing all of our news headlines. To do so, we go over the list of documents in our training sample again and again.
processed_docs = []
processed_docs.append(preprocess(doc))
'''
Preview 'processed_docs'
'''
print(processed_docs[:2])
for doc in newsgroups_train.data:
Now we’ll use ‘processed docs’ to construct a dictionary that contains the number of times each word appears in the training set. To do so, call it ‘dictionary’ and provide processed docs to gensim.corpora.Dictionary().
Creating a bag of words from a text
Before topic identification, we transform the tokenized and lemmatized text into a bag of words. We can think of this as a dictionary with the key being the word and the value being the number of times that word appears in the corpus.
Using gensim.corpora.Dictionary, create a dictionary from ‘processed docs’ that contains the number of times a term appears in the training set and name it ‘dictionary.’
dictionary = gensim.corpora.Dictionary(processed_docs)
We have to check whether the dictionary has been created or not
count = 0
for k, v in dictionary.iteritems():
print(k, v)
count += 1
if count > 10:
break
Output:
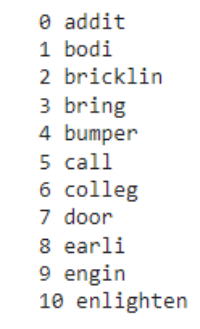
Filter extremes Gensim
Remove any tokens that appear on the list.
- greater than no above documents (absolute number) or
- fewer than no below documents (absolute number) (fraction of total corpus size, not the absolute number).
- Only keep the first keep n most common tokens after (1) and (2). (or keep all if None).
Syntax:
filter_extremes(no_below=5, no_above=0.5, keep_n=100000)
dictionary.filter_extremes(no_below=15, no_above=0.1, keep_n= 100000)
We can also filter out words that appear infrequently or frequently.
We now use the dictionary object we have generated to convert each pre-processed page into a bag of words. i.e., we develop a dictionary for each document that reports how many terms and how many times those words appear.
Gensim doc2bow
Convert a document (a list of words) to a list of (token id, token count) 2-tuples in the bag-of-words format. Each word is taken to be a normalized and tokenized string (either Unicode or utf8-encoded). Before invoking this function, apply tokenization, stemming, and other preprocessing to the words in the document.
We have to create a dictionary for each document with the Bag-of-words model, in which we report how many words and how many times those words appear. ‘bow corpus’ is a good place to save this.
bow_corpus = [dictionary.doc2bow(doc) for doc in processed_docs]
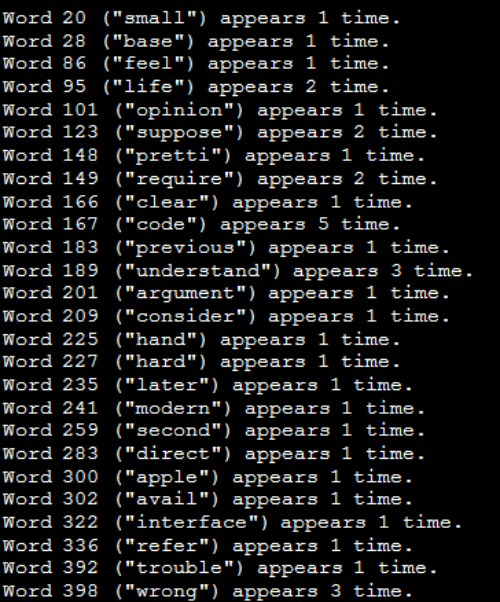
Now, to preview BOW for our preprocessed sample document 11
document_num = 11
bow_doc_x = bow_corpus[document_num]
for i in range(len(bow_doc_x)):
print(“Word {} (“{}”) appears {} time.”.format(bow_doc_x[i][0],
dictionary[bow_doc_x[i][0]],
bow_doc_x[i][1]))
Using Bag of Words to run LDA
In the document corpus, we’re aiming for ten subjects.
To parallelize and speed up model training, we’ll execute LDA on all CPU cores.
The following are some parameters we’ll be adjusting:
1) The model retrieves the requested number of latent themes—defined by num_topics—from the training corpus.
2) The id2word mapping converts word ids (integers) into words (strings). We use it for debugging, printing topics, and determining the vocabulary size.
3) The number of extra processes to use for parallelization is the number of workers. By default, we use all available cores.
4) The hyperparameters alpha and eta affect the sparsity of the document-topic (theta) and topic-word (lambda) distributions, respectively. For the time being, these will be the default values (the default value is 1/num topics).
We know the subject distribution per document as Alpha.
High alpha: Each document has a mix of themes (documents appear similar to each other).
Low alpha: Each document comprises a few subjects.
Eta refers to the per-topic word distribution.
High eta: Each topic contains a variety of terms (topics appear similar to each other).
Low eta: Each topic comprises a little number of words.
Because we can use the gensim LDA model, this is fairly straightforward. The number of subjects in the data collection must be specified. Let’s say we begin with eight distinct subjects. Number of passes refers to the number of training passes over the document.
gensim.models will train our LDA model. LdaMulticore and place it in the ‘LDA model’ folder.
lda_model = gensim.models.LdaMulticore(bow_corpus, num_topics = 8, id2word = dictionary, passes = 10, workers = 2)
After training the model, we’ll look at the words that appear in that topic and their proportional importance for each one.
for idx, topic in lda_model.print_topics(-1):
print("Topic: {} nWords: {}".format(idx, topic ))
print("n")
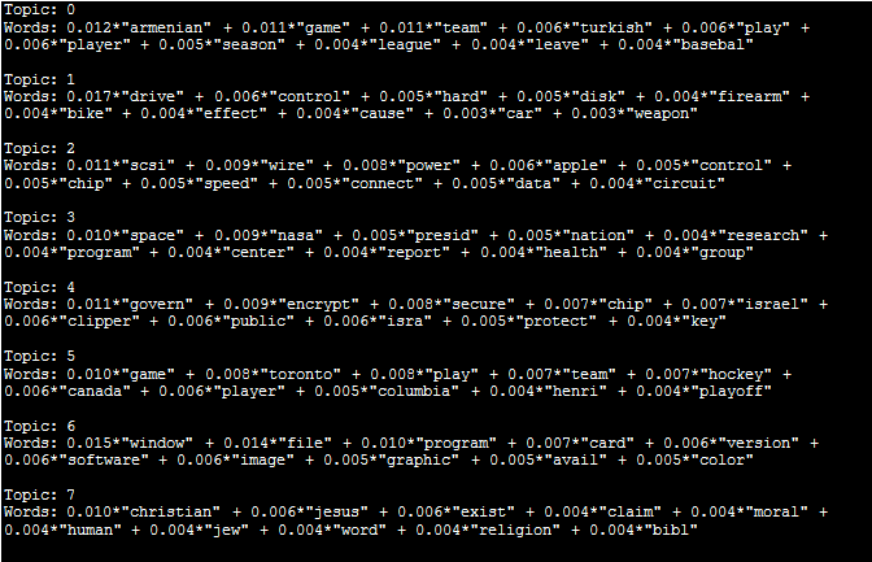
Labeling the topics
What categories were you able to derive from the terms in each topic and their corresponding weights?
- 0: Gun Violence
- 1: Sports
- 2: Politics
- 3: Space
- 4: Encryption
- 5: Technology
- 6: Graphics Cards
- 7: Religion
Testing Model Phase
Preprocessing of data for a previously unseen document
num = 70 unseen_document = newsgroups_test.data[num] print(unseen_document)
Output:
bow_vector = dictionary.doc2bow(preprocess(unseen_document))
for index, score in sorted(lda_model[bow_vector], key=lambda tup: -1*tup[1]):
print("Score: {}t Topic: {}".format(score, lda_model.print_topic(index, 5)))

That’s all there is to it! The model has been completed. Let’s look at how to interpret it and see if the results make sense.
The model produces an output of eight subjects, each of which is classified by a set of words. The LDA model does not give such words a topic name.
Evaluation of the Model
1) The model performed admirably in extracting the data set’s distinct topics, which we can check because we know the target names.
2) The model is extremely fast. In minutes, I could extract topics from a data set.
3) It is assumed that the data set contains discrete subjects. As a result, if the data set is a collection of random tweets, the model findings may be difficult to interpret.
EndNotes
1) By incorporating both the LDA topic probabilities and the sentence embeddings, the contextual topic identification model takes advantage of both bag-of-words and contextual information.
2) Although LDA performs well for topic identification tasks it struggles with brief texts with brief text to model and documents that do not explain the topic coherently. It’s also limited because it’s based on a bag of words.
3) When texts are coherent within themselves, bag-of-words information (LDA or TF-IDF) is excellent for identifying topics by detecting frequent words. When texts are incoherent (in terms of word choice or sentence meaning), more information is required to reflect the texts’ ideas.
Conclusion
With this, we have learnt how to use the bag-of-words strategy to identify a topic in this guide. We also learnt about LDA using ‘gensim,’ a strong open-source NLP library.
The document-term-matrix represents the terms included in the corpus, and their performance depends on them. Because this matrix is sparse, lowering its dimensions may help the model perform better. However, because our corpus was small, we can be pretty confident on the results we got.
Hello, my name is Lavanya, and I’m from Chennai. I am a passionate writer and enthusiastic content maker. The most intractable problems always thrill me. I am currently pursuing my B. Tech in Computer Engineering and have a strong interest in the fields of data engineering, machine learning, data science, and artificial intelligence, and I am constantly looking for ways to integrate these fields with other disciplines such as science and computer to take further my research goals.





